Machine Learning Pipeline
Welcome to my demo AI/ML workflow application for cargo inspection end-users. This is a purpose-built system, not a general-purpose AI or LLM. It focuses on 3D volumetric data and streamlines the workflow into four steps: data collection, tagging, model training, and inference. Built with C++, LibTorch, and JavaScript, and deployed on AWS, it demonstrates how applied research can be turned into a practical, real-world solution.
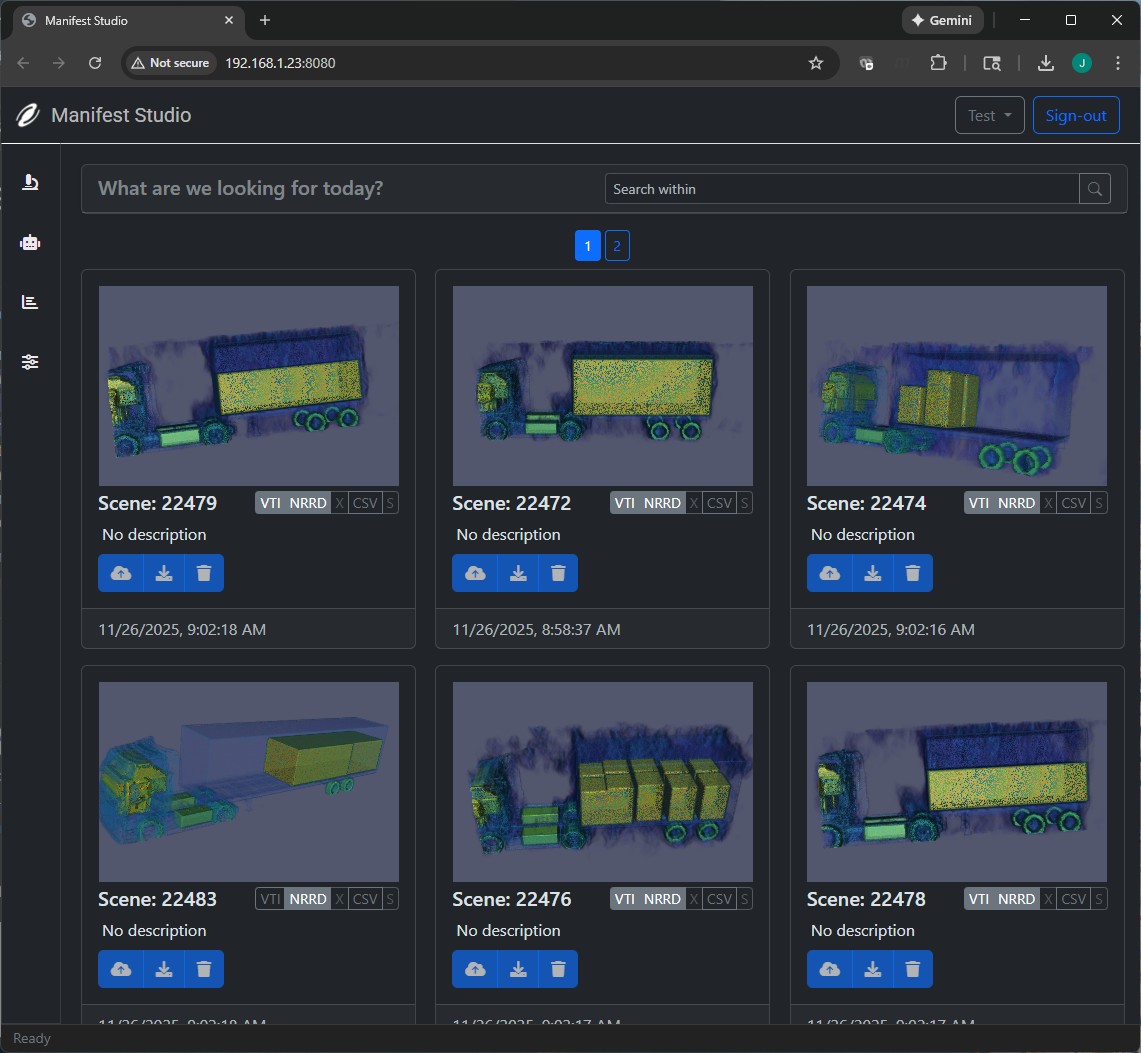
Data Collection
Collecting 3D volumetric data is one thing but keeping it organized is another. This involves ensuring data integrity, managing metadata, quality output starts here. Uses S3 for storage, DynamoDB for metadata, and Cognito for user authentication.
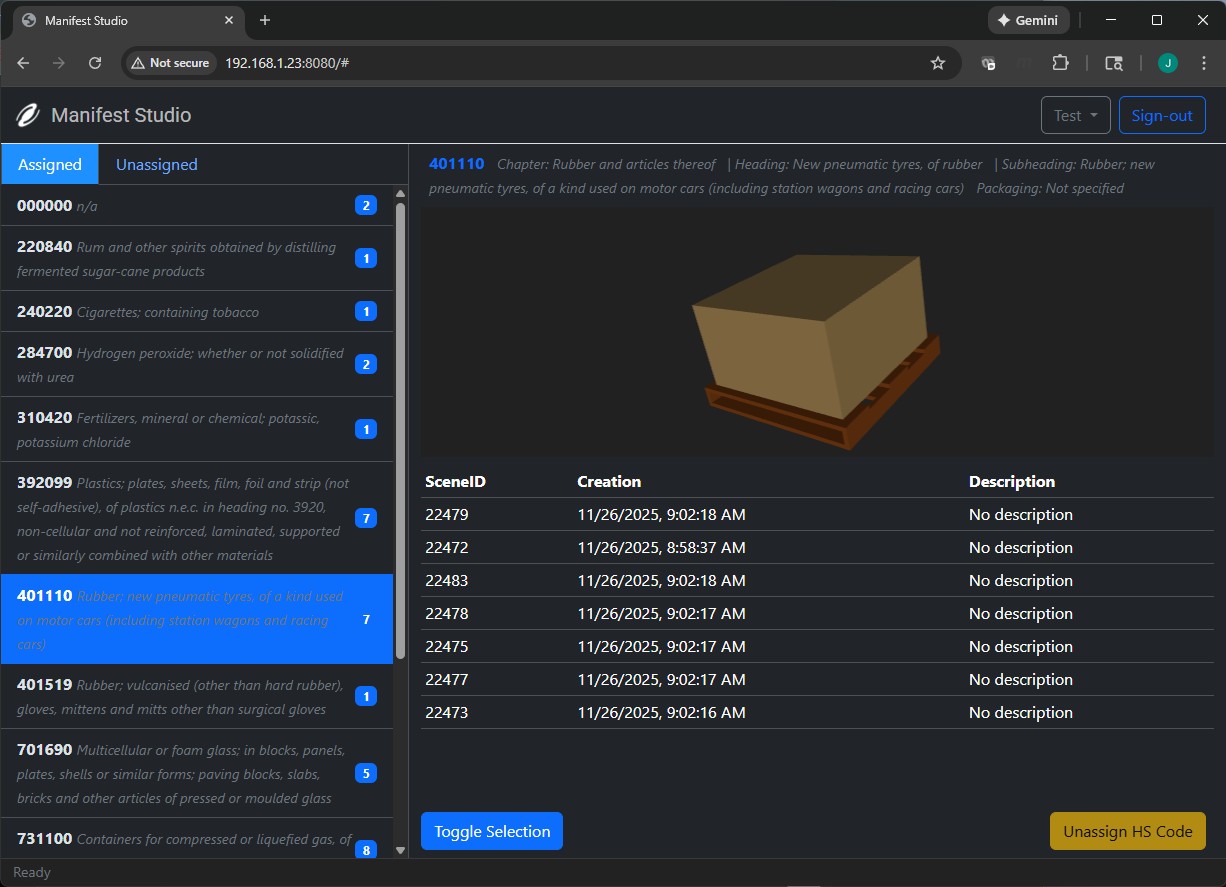
Data Tagging
Tagging data is crucial for model training. Here 3D volumetric data is labeled by HS Code derived using Gemini AI ensuring the dataset is consistent. What's also unique about this particular instance is that custom 3D models are generated based on tagged data. Materials are assigned appropriate colors and packaging is determined by ground truth dimensions. For example, liquids such as oil will be rendered as dark colored barrels whereas dry goods will be rendered as boxes or bags. Pallets are automatically generated based on the dimensions of the items.
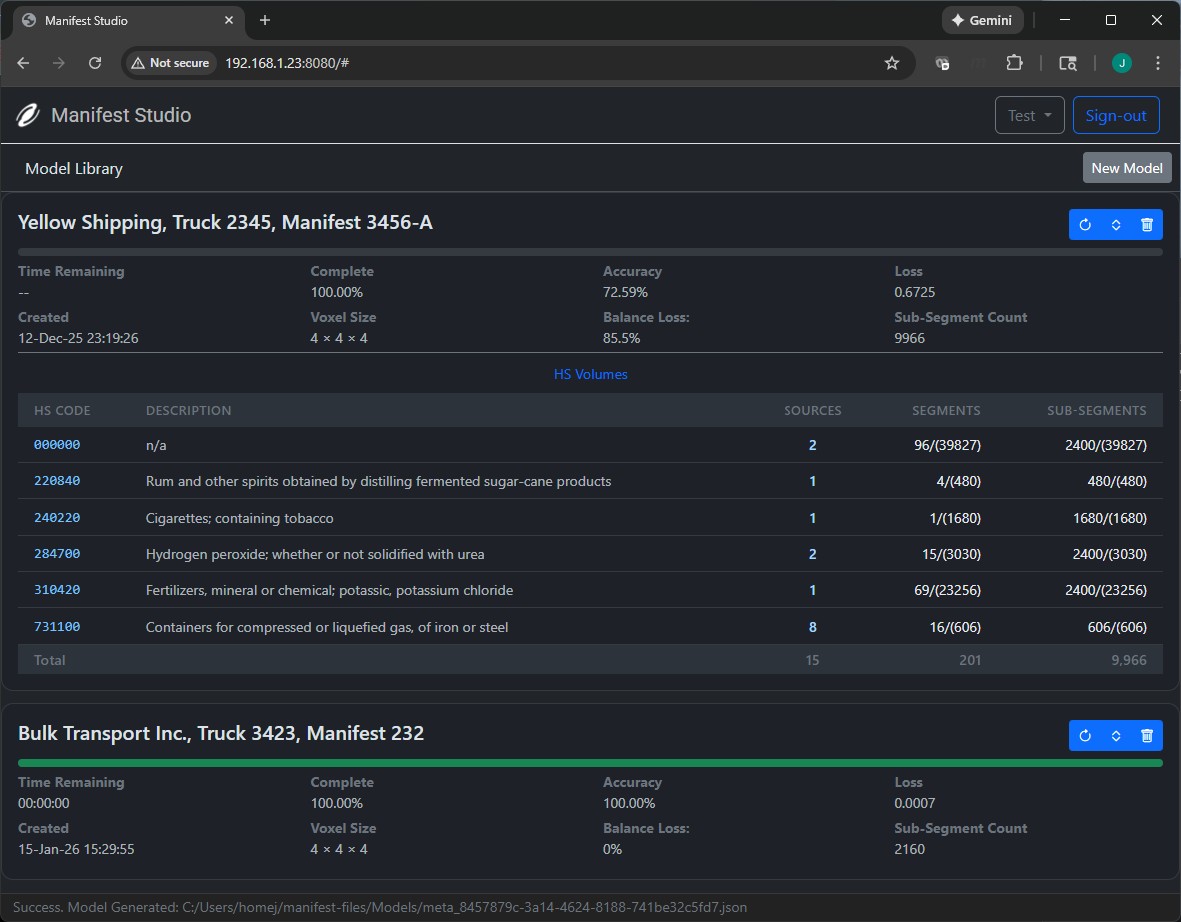
Model Training
Training runs on a custome C++ backend using PyTorch/LibTorch. This step is computationally expensive so data is off-loaded to a GPU instance to improve performance.
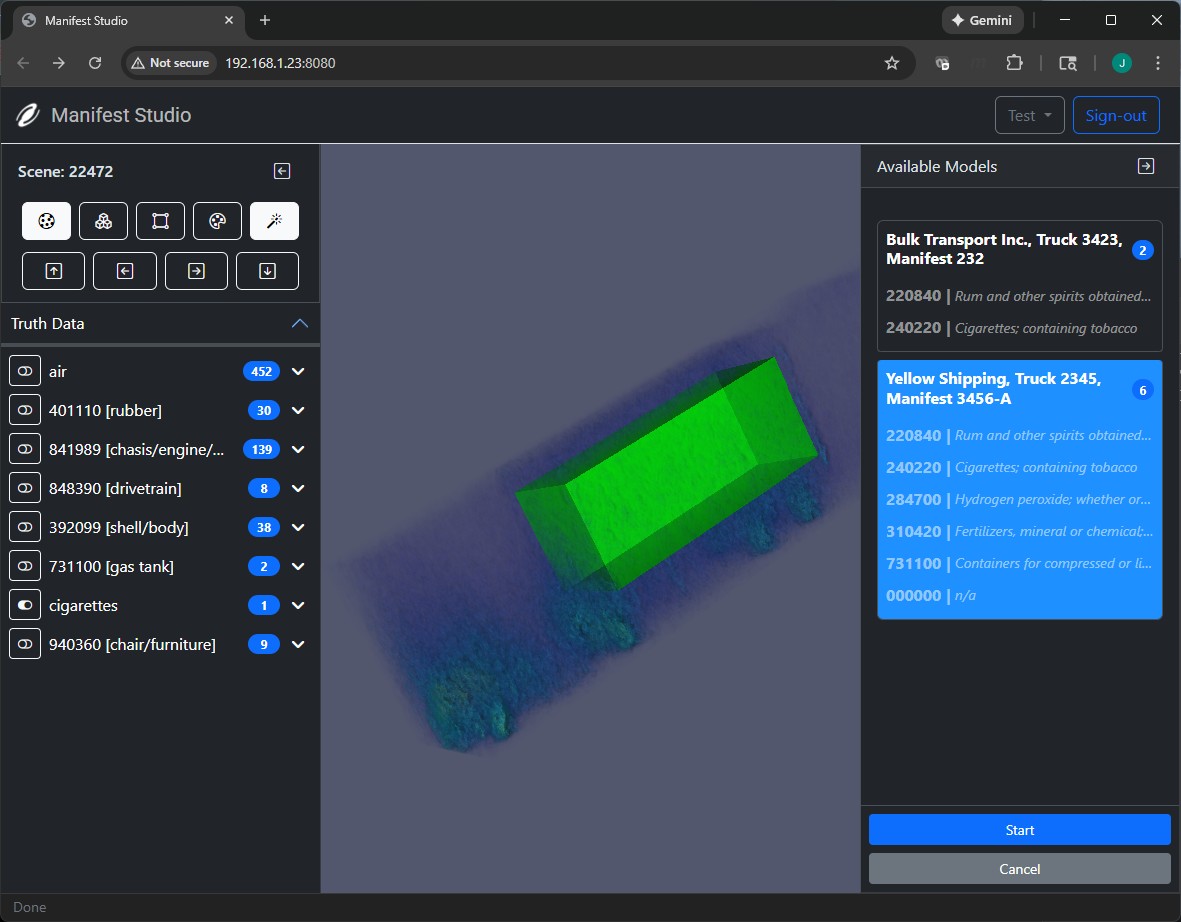
Inference
Once the model is trained, it can be used to make predictions on new data. This step involves applying the trained model to new 3D volumetric data to generate predictions or classifications. Rendering is performed using VTV.js.